New conifer applications
I recently learned about three new applications making use of conifer to deploy BDTs to FPGAs with high performance.
What excited me - as the creator and maintainer of conifer - about the different use cases is how different they are, while all still benefiting from fast and efficient inference of BDTs.
ATLAS L0 Tau Trigger
Firstly, an application from the ATLAS experiment L0 trigger. This is closest to the type of application that conifer was originally created for: extremely low latency triggering at the Large Hadron Collider experiments. In 2024, ATLAS are using BDTs to reconstruct tau leptons from signals in the calorimeter. As a trigger application, this example has a tight latency budget of 60 ns, and a resource budget constrained by fitting in the same FPGA that’s computing the input features to the BDT.
This plot shows the seperation between simulated signal and background data, emulated using the conifer cpp backend integrated in the ATLAS software framework, from here.

See more here from a talk by David Reikher at the FastML workshop in 2023. David also contributed to the “manually unrolled” implementation of the Vitis HLS backend.
Some interesting stats for conifer users:
- frontend:
xgboost- number of trees: 32
- maximum depth: 2
- pruned
- backend:
Vitis HLS- latency 12 clock cycles @ 200 MHz (60 ns)
- target device: AMD Virtex 7 FPGA
Tracking detector frontend data reduction
J. Gonski et al, Embedded FPGA Developments in 130nm and 28nm CMOS for Machine Learning in Particle Detector Readout, 2024, arXiv:2404.17701v1
A team from Stanford and SLAC have shown that a tiny Decision Tree model running in an eFPGA at the periphery of a particle tracking detector frontend ASIC can be used to filter data from pile-up events. The main goal of the work was to demonstrate the use of eFPGAs in frontend ASICs, which adds an element of reconfigurability to devices that are otherwise fixed in function and expected to operate for many years without replacement. In order to show the potential for data reduction at source, the authors trained a single Decision Tree to classify whether a charged particle depositing charge in the sensor carried a transverse momentum pT > 2 GeV. Measurements from tracks with transverse momentum below this threshold could be filtered out.
The image shows the ASIC mounted on a mezzanine card, from the reference above.
![]()
The model needs to be small due to the extremely limited resources in the eFPGA: only 448 LUTs in total. By comparison, the AMD Ultrascale+ devices that I’m used to using for the CMS Level 1 Trigger upgrade have around 3.8 million LUTs. Nonetheless, a tree with a depth of 5 was able to reject background tracks with some discrimination power, and fit in the device.
- Frontend:
scikit-learn- number of trees: 1
- maximum depth: 5
- Backend:
HLS- Followed by non-standard toolchain for integration into eFPGA
- Resource Usage: 294 LUTs
- Latency: 25 ns
- Target Device: eFPGA from FABulous
- 448 LUTs available
Enhancing blood vessel segmentation
Alsharari M et al. Efficient Implementation of AI Algorithms on an FPGA-based System for Enhancing Blood Vessel Segmentation. doi:10.21203/rs.3.rs-4351485/v1.
In this work, the authors demonstrate methods to perform performing image segmentation to identify blood vessels in a proposed surgical imaging device. Deep Neural Network architectures like U-Net are state of the art in image segmentation, but this work shows the Decision Forests can achieve a segmentation performance that’s close to those, while being capable of much faster inference. A GBDT, deployed to a Kria SoM with conifer, achieved the best FPS with segmentation performance competitive with U-Net models.
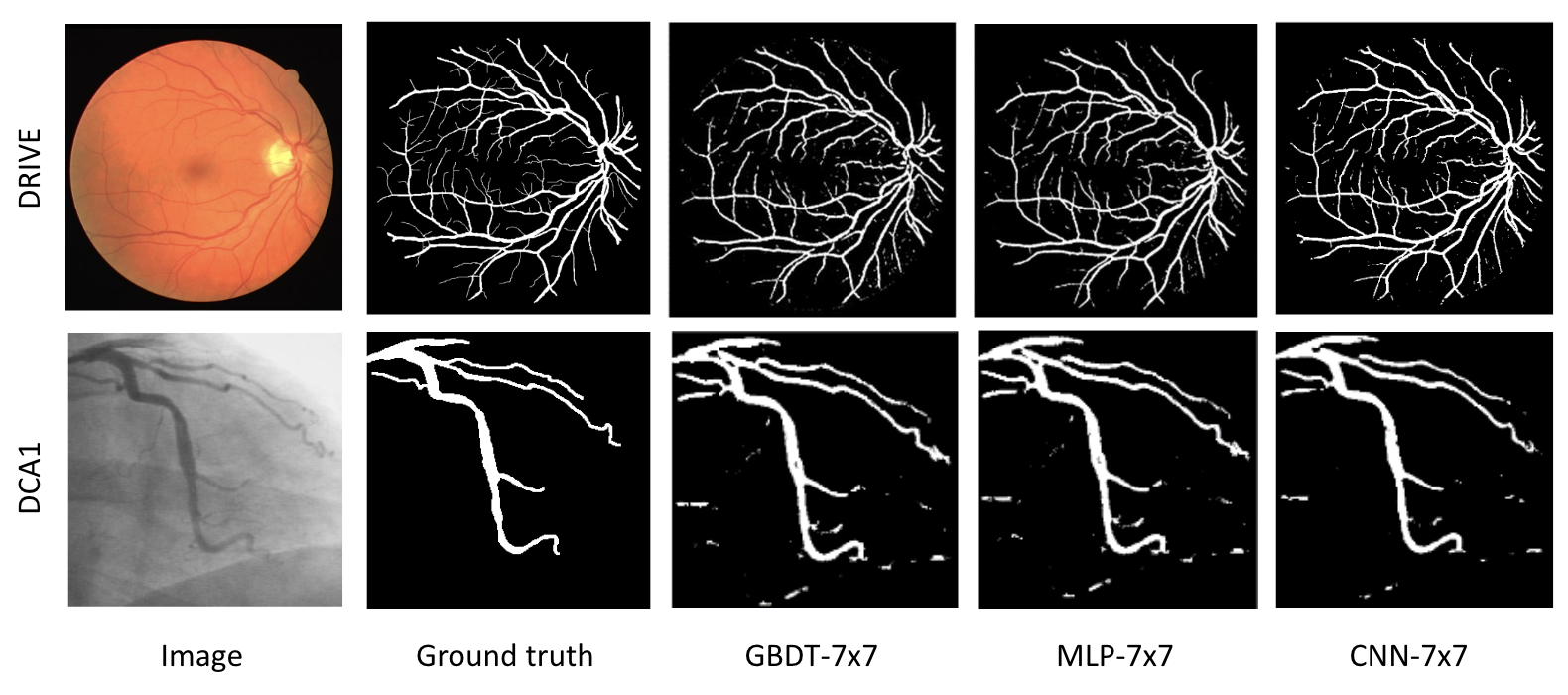
The image shows the image, ground truth segmenation, and predictions for different models. The three models were deployed to the Kria KV260 System-on-Module device using conifer for the BDT and hls4ml for the two Neural Networks. Inference of the MLP and CNN models is executed with 13 FPS and 4 FPS respectively, while the GBDT infers at 286 FPS (all on the same 512x512 image size). Power during inference was measured around 3.8 W for the GBDT.
This example shows that conifer has relevance and high performance in the space of edge devices. In these domains the main constraints are typically cost, resources, and power rather than the extreme low latency and high throughput of the LHC case that conifer was initially developed for.
The paper also describes how the images are preprocessed into tiles with a sliding window for inference on smaller chunks.
- Frontend:
ONNX(catboostfor training)- number of trees: 100
- maximum depth: 3
- Backend:
Vitis HLS - Target Device: AMD Kria KV260
- 1779 FPS, 3.85 W on 240x240 images
- 286 FPS, 3.81 W on 512x512 images